[Kaggle] LMSYS Chatbot Arena - 최고의 챗봇 선택하기 ( Chat gpt? Gemini? Grok? 누가 승자일까? )
🥇🆚🥈 LMSYS Chatbot Arena - 최고의 챗봇 선택하기
이번글은 좀 다르게 좀 길어지더라도 글이 끊어지지 않고 전체 flow를 한 글에 정리해보려고 합니다!
https://www.kaggle.com/code/addisonhoward/lmsys-kerasnlp-starter
LMSYS: KerasNLP Starter
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
코드는 해당 노트북을 보며 공부했습니다.
A. "LMSYS Chatbot Arena" 대회란 무엇일까요?
Kaggle의 "LMSYS Chatbot Arena" 대회는 사용자들이 두 개의 서로 다른 대규모 언어 모델(Large Language Model, LLM), 즉 우리가 흔히 챗봇이라고 부르는 AI와 대화를 나눈 후, 어떤 모델의 답변이 더 만족스러웠는지에 대한 '인간의 선호도'를 예측하는 것을 목표로 합니다.
Chatbot Arena 자체는 UC 버클리, UCSD, CMU 등의 연구자들이 개발한 플랫폼으로, 다양한 LLM들을 사용자들이 직접 테스트하고 그 성능을 비교·평가할 수 있게 해 줍니다.사용자들은 두 챗봇에게 동일한 질문을 하고, 받은 답변들을 비교하여 어느 쪽이 더 나은지, 혹은 비슷한 수준인지 투표합니다. ( 은근 투표하는거 재밌어요! ) 이 대회는 바로 이렇게 수집된 실제 사용자들의 평가 데이터를 기반으로 진행됩니다. 이 과제는 단순히 정답을 맞히는 것을 넘어, 인간의 주관적인 만족도를 AI가 얼마나 잘 이해하고 예측할 수 있는지를 평가한다는 점에서 흥미롭습니다.
B. 데이터 이해하기: 프롬프트, 챗봇 응답, 그리고 승자
이 대회에서 참가자들에게 제공되는 데이터는 주로 사용자가 챗봇에게 던진 질문(프롬프트), 그리고 그에 대한 두 챗봇(모델 A, 모델 B)의 응답, 마지막으로 어떤 모델의 응답이 더 좋았는지에 대한 판정 결과로 구성됩니다.
| 파일 이름 | 주요 열 (Columns) | 설명 | 사용자 목적 |
| train.csv | id, model_a, model_b, prompt, response_a, response_b, winner_model_a, winner_model_b, winner_model_tie | 각 상호작용의 고유 ID, 모델 A/B의 이름, 사용자 프롬프트, 모델 A/B의 응답, 그리고 모델 A 승리, 모델 B 승리, 무승부 여부를 나타내는 정답 레이블. | AI 모델을 학습시키는 데 사용되는 데이터. |
| test.csv | id, prompt, response_a, response_b | 학습 데이터와 유사하나, 모델 이름과 정답 레이블(winner_model_ 열)이 없음. | 학습된 AI 모델의 성능을 평가하기 위한 미지의 데이터. |
| sample_submission.csv | id, winner_model_a, winner_model_b, winner_model_tie | 예측 결과를 어떤 형식으로 제출해야 하는지 보여주는 예시 파일. 각 ID에 대해 모델 A 승리, 모델 B 승리, 무승부일 확률값을 제출해야 함. | 예측 결과 제출 형식의 기준. |
- train.csv (학습 데이터): 이 파일에는 모델을 '가르치는' 데 필요한 모든 정보가 들어있습니다.
- id: 각 데이터 행(즉, 각 대화 사례)을 구분하는 고유한 번호입니다.
- model_a, model_b: 대화에 참여한 두 챗봇 모델의 이름입니다. (이 정보는 test.csv에는 제공되지 않습니다.)
- prompt: 사용자가 두 모델에게 동일하게 입력한 질문이나 지시사항입니다.
- response_a, response_b: 위 prompt에 대해 각각 모델 A와 모델 B가 생성한 답변입니다.
- winner_model_a, winner_model_b, winner_model_tie: 이 세 개의 열이 바로 AI 모델이 예측해야 할 '정답'에 해당합니다. 예를 들어, winner_model_a 열의 값이 1이면 사용자가 모델 A의 답변을 더 선호했다는 의미이고, winner_model_b 가 1이면 모델 B를, winner_model_tie 가 1이면 두 답변이 비슷하거나 둘 다 별로였다고 판단했다는 의미입니다. 이 중 하나만 1의 값을 가집니다.
- test.csv (테스트 데이터): 이 파일은 학습된 AI 모델의 실제 성능을 평가하는 데 사용됩니다. train.csv와 구성이 유사하지만, 가장 중요한 차이점은 model_a, model_b의 이름과 정답에 해당하는 winner_model_ 열들이 빠져 있다는 것입니다. 참가자는 이 데이터에 대해 자신의 모델로 예측값을 생성해야 합니다.
- sample_submission.csv (제출 파일 예시): 캐글 대회에서는 예측 결과를 정해진 형식에 맞춰 제출해야 합니다. 이 파일은 그 형식을 보여주는 예시입니다. 각 id에 대해 모델이 예측한 winner_model_a, winner_model_b, winner_model_tie가 될 확률값을 제출해야 합니다.
C. 대규모 언어 모델 (LLMs): 똑똑한 챗봇 쉽게 이해하기
대규모 언어 모델(Large Language Model, LLM)은 최근 AI 분야에서 가장 주목받는 기술 중 하나입니다. LLM은 이름에서 알 수 있듯이 '아주 많은 양의' 텍스트 데이터를 학습하여, 마치 사람처럼 글을 이해하고, 요약하고, 질문에 답하고, 심지어 새로운 글을 창의적으로 생성할 수 있는 능력을 갖춘 AI 모델을 말합니다. 우리가 일상에서 접하는 챗GPT(ChatGPT)나 구글의 제미나이(Gemini)와 같은 서비스들이 바로 이 LLM 기술을 기반으로 하고 있습니다.
LLM은 수십억, 수천억 개에 달하는 단어와 문장들로 이루어진 방대한 데이터를 통해 언어의 패턴, 문법 구조, 단어 간의 의미 관계, 그리고 세상의 다양한 지식까지 학습합니다. 이 과정은 마치 한 사람이 평생 읽을 수 있는 양보다 훨씬 많은 책과 글을 읽고 그 내용을 모두 기억하는 것과 유사하다고 비유할 수 있습니다. 덕분에 LLM은 주어진 문맥을 파악하고, 다음에 이어질 가장 자연스러운 단어나 문장을 매우 높은 정확도로 예측할 수 있으며, 이를 바탕으로 다양한 언어 관련 작업을 수행합니다.
D. KerasNLP: Keras로 텍스트 AI를 더 쉽게
KerasNLP는 자연어 처리(Natural Language Processing, NLP) 모델을 케라스(Keras) 환경에서 더욱 쉽고 효율적으로 개발하고 사용할 수 있도록 특별히 설계된 라이브러리입니다. KerasNLP는 케라스의 장점을 그대로 계승하면서, 텍스트 데이터를 다루는 데 필요한 다양한 기능들을 추가한 일종의 'NLP 확장팩'이라고 생각할 수 있습니다.
KerasNLP를 사용하면 Gemma, GPT, 그리고 이 노트북의 핵심인 DeBERTa와 같은 유명하고 강력한 LLM들을 미리 학습된 가중치(pretrained weights)와 함께 단 몇 줄의 코드로 쉽게 불러올 수 있습니다. 이렇게 불러온 모델들은 바로 사용하거나, 특정 작업에 더 적합하도록 '미세조정(fine-tuning)'이라는 추가 학습 과정을 거칠 수 있습니다.
또한, 케라스는 텐서플로우(TensorFlow), 파이토치(PyTorch), JAX와 같은 여러 주요 딥러닝 백엔드 프레임워크 위에서 동작할 수 있는 유연성을 제공하는데, KerasNLP 역시 이러한 멀티-백엔드 특성을 지원합니다. 이는 개발자가 선호하는 백엔드를 선택하여 KerasNLP 코드를 거의 변경 없이 실행할 수 있게 해 주어, 개발의 편의성과 이식성을 크게 높여줍니다. 이러한 특징들 덕분에 KerasNLP는 복잡한 NLP 작업을 추상화하여 사용자가 모델의 핵심 로직에 더 집중할 수 있도록 도와주므로, 특히 NLP 분야에 입문하는 사람들에게 매우 유용한 도구입니다.
이제 배경지식을 갖추었으므로, 코드를 보면서 해당 문제를 풀어봅시다!
🔎 글 개요
이 노트북은 KerasNLP의 공유 가중치 전략 을 사용하여 이 대회를 위해 DebertaV3 모델을 미세 조정하는 과정을 안내합니다. 이 전략은 객관식 문제(MCQ) 모델의 학습 방식과 유사합니다. 또한, 더 빠른 학습 및 추론을 위해 혼합 정밀도를 사용할 것입니다.
🗂️ 글 내부 목차
1. 프로젝트 설정 및 환경 구성
1.1 라이브러리 가져오기 및 버전 확인
모든 코딩 작업의 시작은 필요한 도구들, 즉 라이브러리들을 불러오는(import) 것입니다. KerasNLP가 어떤 딥러닝 엔진(JAX, TensorFlow, PyTorch 중 하나)을 기반으로 동작할지 명시적으로 지정하는 코드가 포함되었습니다.
os.environ = "jax"와 같은 코드는 JAX를 백엔드로 사용하겠다는 의미입니다
import os
os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
import keras_nlp
import keras
import tensorflow as tf
import numpy as np
import pandas as pd
from tqdm import tqdm
import json
import matplotlib.pyplot as plt
import matplotlib as mpl
import plotly.express as px
- os.environ을 이용한 명시적 지정: os.environ["KERAS_BACKEND"] = "jax" 코드는 Keras 라이브러리가 메모리에 로드되기 전에 어떤 백엔드 엔진을 사용할지 운영 체제의 '환경 변수'를 통해 명확하게 지정하는 역할을 합니다. 이렇게 하면, 이후에 import keras나 import keras_nlp가 실행될 때 Keras는 지정된 'JAX'를 기반으로 모든 연산을 설정하고 준비합니다.
이 설정을 통해 사용자는 자신의 프로젝트 요구사항이나 선호하는 프레임워크에 맞춰 Keras의 실행 기반을 선택할 수 있습니다. 만약 이 설정을 생략하면 Keras는 기본값(주로 TensorFlow)으로 설정되거나, 기존 설정에 따라 동작하게 됩니다. 따라서 특정 백엔드를 사용하고자 한다면, Keras를 임포트 하기 전에 이처럼 명시적으로 지정해 주는 것이 중요합니다.
print("TensorFlow:", tf.__version__)
print("Keras:", keras.__version__)
print("KerasNLP:", keras_nlp.__version__)TensorFlow: 2.16.1
Keras: 3.3.3
KerasNLP: 0.15.11.2 Configuration
이 클래스는 코딩 프로젝트에서 사용할 여러 가지 중요한 설정값들을 한 곳에 모아두는 '설정 보관함' 역할을 합니다. 이렇게 하면 나중에 설정을 변경하거나 확인할 때 편리합니다.
class CFG:
seed = 42 # Random seed
preset = "deberta_v3_extra_small_en" # Name of pretrained models
sequence_length = 512 # Input sequence length
epochs = 3 # Training epochs
batch_size = 16 # Batch size
scheduler = 'cosine' # Learning rate scheduler
label2name = {0: 'winner_model_a', 1: 'winner_model_b', 2: 'winner_tie'}
name2label = {v:k for k, v in label2name.items()}
class_labels = list(label2name.keys())
class_names = list(label2name.values())- seed = 42: '무작위 시드'입니다. 코드를 실행할 때마다 동일한 결과를 얻고 싶을 때 사용합니다. (실험의 재현성을 위해)
- preset = "deberta_v3_extra_small_en": 바로 이 부분이 사용할 사전 학습된 모델의 이름입니다.
- sequence_length = 512: 모델에 입력할 텍스트의 최대 길이를 512개의 토큰(단어나 하위 단어)으로 정합니다.
- epochs = 3: 모델을 훈련 데이터로 총 3번 반복 학습시킵니다.
- batch_size = 16: 한 번에 16개의 데이터 샘플을 묶어서 모델을 학습시킵니다.
- scheduler = 'cosine': 학습률을 '코사인' 방식으로 조절합니다.
- label2name, name2label, class_labels, class_names: 이 부분은 모델이 예측해야 할 결과(클래스 또는 레이블)에 대한 정보를 담고 있습니다. 예를 들어, 0번은 'winner_model_a', 1번은 'winner_model_b' 등으로 맵핑하는 규칙입니다.
DeBERTa V3 모델이란?
DeBERTa (Decoding-enhanced BERT with disentangled attention): DeBERTa는 BERT 모델을 개선한 강력한 언어 모델입니다. 이름처럼 '분리된 어텐션(disentangled attention)'이라는 핵심 기술을 사용합니다. 이는 단어의 '내용'과 '위치' 정보를 분리해서 처리함으로써 문맥을 더 정교하게 이해하는 데 도움을 줍니다. ( 어텐션에 대해선 대학에서 얼핏 배운 내용이 다여서 일단 넘어가겠습니다. )
- V3의 특징: DeBERTa V3는 이전 버전에 비해 훨씬 효율적이고 성능이 개선된 버전입니다. 특히 ELECTRA라는 모델과 유사한 'Replaced Token Detection'이라는 방식으로 사전 학습되어, 적은 계산량으로도 높은 성능을 달성하는 것으로 알려져 있습니다.
- extra_small_en: 이는 모델의 크기(extra_small은 가장 작은 버전 중 하나)와 언어(en은 영어)를 나타냅니다. Gemma처럼 거대한 LLM은 아니지만, 특정 자연어 이해(NLU) 작업에서는 매우 효율적이면서도 뛰어난 성능을 보여줍니다. 특히, 문장 분류나 개체명 인식과 같은 작업에 강점을 보입니다.
1.3 Reproducibility (재현성)
각 실행에서 비슷한 결과를 생성하기 위해 난수 시드에 대한 값을 설정합니다.
keras.utils.set_random_seed(CFG.seed)1.4 Mixed Precision (혼합 정밀도)
딥러닝 모델을 학습시킬 때는 보통 float32라는 32비트 부동 소수점 숫자를 사용합니다. 이는 계산의 정확도를 높여주지만, 꽤 많은 GPU 메모리를 차지하고 계산 시간도 더 걸릴 수 있습니다.
혼합 정밀도(Mixed Precision)는 이러한 float32와, 그보다 크기가 절반인 float16(16비트)을 지능적으로 섞어 쓰는 기술입니다.
이를 통해 동일한 GPU 환경에서도 더 큰 모델을 학습시키거나, 한 번에 처리하는 데이터 양인 배치 크기(batch_size)를 늘릴 수 있습니다.
Keras는 이 혼합 정밀도 기술을 매우 쉽게 적용할 수 있도록 지원합니다. 모델의 특정 레이어는 속도를 위해 float16으로 계산하고, 수치적 안정성이 중요한 부분(예: 손실 계산, 최종 출력 등)은 float32로 유지하는 복잡한 과정을 Keras가 자동으로 관리해 줍니다.
keras.mixed_precision.set_global_policy("mixed_float16")
1.5 데이터셋 경로 설정
데이터셋이 존재하는 폴더로 BASE_PATH를 설정합니다.
BASE_PATH = '/kaggle/input/llm-classification-finetuning'2. 데이터 이해 및 탐색
여기에서 데이터 구조를 설명했었습니다. 다시 한번 보고 오시죠!
주의
원래 데이터에는 하나의 '상호작용' (행) 데이터 안에는 여러 번 주고받은 대화(여러 개의 프롬프트와 그에 대한 응답들)가 포함될 수 있습니다. 예를 들어, 사용자가 질문하고 챗봇이 답하고, 사용자가 다시 질문하고 챗봇이 답하는 식입니다.
- 이 노트북의 방식: 하지만 이 노트북에서는 분석이나 학습을 단순화하기 위해, 각 상호작용에서 단 하나의 프롬프트(와 그에 대한 응답)만 골라서 사용합니다. 즉, 여러 번의 대화가 있더라도 그중 대표적인 한 쌍만 사용하겠다는 의미입니다.
- 저장 형태: 데이터가 저장된 파일(CSV)은 판다스(Pandas) 데이터프레임으로 불러왔을 때, 프롬프트나 응답 데이터가 실제 파이썬 리스트(List)가 아니라, 리스트처럼 생긴 '문자열(String)'로 저장되어 있습니다.
따라서 eval() 함수를 사용해서 이 문자열을 실제 파이썬 리스트로 변환할 것입니다.
2.1 훈련 및 테스트 데이터 로드 및 정제
# Load Train Data
df = pd.read_csv(f'{BASE_PATH}/train.csv')
# Sample data
# df = df.sample(frac=0.10)
# Take the first prompt and its associated response
df["prompt"] = df.prompt.map(lambda x: eval(x)[0])
df["response_a"] = df.response_a.map(lambda x: eval(x.replace("null","''"))[0])
df["response_b"] = df.response_b.map(lambda x: eval(x.replace("null", "''"))[0])
# Label conversion
df["class_name"] = df[["winner_model_a", "winner_model_b" , "winner_tie"]].idxmax(axis=1)
df["class_label"] = df.class_name.map(CFG.name2label)
# Show Sample
df.head()
# Load Test Data
test_df = pd.read_csv(f'{BASE_PATH}/test.csv')
# Take the first prompt and response
test_df["prompt"] = test_df.prompt.map(lambda x: eval(x)[0])
test_df["response_a"] = test_df.response_a.map(lambda x: eval(x.replace("null","''"))[0])
test_df["response_b"] = test_df.response_b.map(lambda x: eval(x.replace("null", "''"))[0])
# Show Sample
test_df.head()
2.2 Contextualize Response with Prompt (응답 맥락화)
이 단계의 핵심 목표는 모델이 응답(Response)을 평가하거나 이해할 때, 그 응답이 어떤 프롬프트(Prompt)에 대한 것인지 명확하게 알게 하는 것입니다. 마치 대화에서 상대방의 대답만 듣는 것이 아니라, 어떤 질문에 대한 대답인지를 함께 알아야 그 의미를 제대로 파악할 수 있는 것과 같습니다.
모델은 (프롬프트, 응답 A)를 보고 A를 평가/학습하고, (프롬프트, 응답 B)를 보고 B를 평가/학습하게 됩니다. 이를 통해 모델은 동일한 질문(맥락) 하에서 어떤 응답이 더 나은지 등을 학습할 수 있습니다.
또한, 일부 텍스트가 이 UTF-8 표준을 따르지 않거나 손상되는 경우가 있습니다. 이런 데이터를 그대로 사용하려고 하면 인코딩 오류(Encoding Error)가 발생하여 프로그램이 중단될 수 있습니다. 오류가 발생할 가능성이 있는 텍스트는 안전하게 무시하고 빈칸("")으로 바꿔버리겠습니다.
# Define a function to create options based on the prompt and choices
def make_pairs(row):
row["encode_fail"] = False
try:
prompt = row.prompt.encode("utf-8").decode("utf-8")
except:
prompt = ""
row["encode_fail"] = True
try:
response_a = row.response_a.encode("utf-8").decode("utf-8")
except:
response_a = ""
row["encode_fail"] = True
try:
response_b = row.response_b.encode("utf-8").decode("utf-8")
except:
response_b = ""
row["encode_fail"] = True
row['options'] = [f"Prompt: {prompt}\n\nResponse: {response_a}", # Response from Model A
f"Prompt: {prompt}\n\nResponse: {response_b}" # Response from Model B
]
return rowdf = df.apply(make_pairs, axis=1) # Apply the make_pairs function to each row in df
display(df.head(2)) # Display the first 2 rows of df
test_df = test_df.apply(make_pairs, axis=1) # Apply the make_pairs function to each row in df
display(test_df.head(2)) # Display the first 2 rows of df
#인코딩 실패 개수 확인하기
df.encode_fail.value_counts(normalize=False)encode_fail
False 56885
True 592 # 오직 1%만 실패함
Name: count, dtype: int642.3 EDA
데이터 셋에서, 어떤 model이 자주 등장하는지, 승리 모델의 분포는 어떤지 확인해 봅시다.
model_df = pd.concat([df.model_a, df.model_b])
counts = model_df.value_counts().reset_index()
counts.columns = ['LLM', 'Count']
# Create a bar plot with custom styling using Plotly
fig = px.bar(counts, x='LLM', y='Count',
title='Distribution of LLMs',
color='Count', color_continuous_scale='viridis')
fig.update_layout(xaxis_tickangle=-45) # Rotate x-axis labels for better readability
fig.show()
counts = df['class_name'].value_counts().reset_index()
counts.columns = ['Winner', 'Win Count']
fig = px.bar(counts, x='Winner', y='Win Count',
title='Winner distribution for Train Data',
labels={'Winner': 'Winner', 'Win Count': 'Win Count'},
color='Winner', color_continuous_scale='viridis')
fig.update_layout(xaxis_title="Winner", yaxis_title="Win Count")
fig.show()
3. 모델링 준비 및 정의
자연어 처리 모델을 만들어 본 경험이 없다면, 이해하는데 오래 걸릴 수 있습니다. 하지만 천천히 학습하면 다 알아들을 순 있어집니다! (제가 바로 그 알아들을 수 만 있는 감자입니다 ㅎㅎ)
3.1 데이터 분할
class_label 열을 기준으로 데이터를 훈련 세트와 검증 세트로 계층화하여 나눕니다.
from sklearn.model_selection import train_test_split # Import package
train_df, valid_df = train_test_split(df, test_size=0.2, stratify=df["class_label"])3.2 전처리
DeBERTa V3 모델에 텍스트 데이터를 입력하기 전에 필요한 전처리(preprocessing) 과정을 정의하고 실행하는 부분입니다. 전처리는 사람이 사용하는 자연어를 모델이 이해할 수 있는 숫자 형태로 바꿔주는 핵심 단계입니다.
DebertaV3Preprocessor를 사용하여 입력 문자열을 토큰화(토큰화 설명 링크)하고 패딩하여 모델 입력(token_ids, padding_mask)으로 변환합니다.
preprocessor = keras_nlp.models.DebertaV3Preprocessor.from_preset(
preset=CFG.preset, # CFG는 초반에 선언했던 class입니다!
sequence_length=CFG.sequence_length, # Max sequence length, will be padded if shorter
)전처리기(Preprocessor) 로드 및 설정:
- preprocessor = keras_nlp.models.DebertaV3Preprocessor.from_preset(...): KerasNLP 라이브러리에서 제공하는 DebertaV3Preprocessor를 불러옵니다. 이 전처리기는 DeBERTa V3 모델에 특화된 방식으로 텍스트를 처리합니다.
- preset=CFG.preset: 이전에 CFG 클래스에 정의해 둔 모델 이름("deberta_v3_extra_small_en")을 가져와 해당 모델에 맞는 전처리 방식을 사용하도록 설정합니다.
- sequence_length=CFG.sequence_length: 모델이 한 번에 처리할 텍스트의 최대 길이(512)를 설정합니다. 입력된 텍스트가 이 길이보다 짧으면 특별한 표시(패딩 토큰)를 채워 길이를 맞추고, 길면 자릅니다.
outs = preprocessor(df.options.iloc[0]) # Process options for the first row
# Display the shape of each processed output
for k, v in outs.items():
print(k, ":", v.shape)샘플 데이터 전처리 및 출력 확인:
- outs = preprocessor(df.options.iloc[0]): 데이터프레임(df)의 options 열에 있는 첫 번째 행(iloc[0])의 데이터를 가져와 실제로 전처리기를 통과시킵니다.
- for k, v in outs.items(): print(k, ":", v.shape): 전처리된 결과(outs)는 딕셔너리 형태로 여러 값을 포함합니다. 각 값(v)이 어떤 형태(shape)로 변환되었는지 출력하여 확인합니다. 주요 출력값은 다음과 같습니다:
- token_ids: 텍스트가 변환된 숫자 ID들의 배열입니다. 각 숫자는 특정 단어나 하위 단어(토큰)에 해당합니다.
- padding_mask: sequence_length를 맞추기 위해 추가된 패딩 토큰이 어느 위치에 있는지 알려주는 마스크입니다. 실제 단어는 1, 패딩 부분은 0으로 표시됩니다.
#options가 2개의 개별적인 텍스트 문자열을 담고 있는 리스트(list)이므로
#2개의 텍스트 샘플이 각각 512개의 토큰 ID (또는 패딩 마스크 값)로 변환되었다.
token_ids : (2, 512)
padding_mask : (2, 512)def preprocess_fn(text, label=None):
text = preprocessor(text) # Preprocess text
return (text, label) if label is not None else text # Return processed text and label if available앞으로 텍스트 데이터를 일괄적으로 전처리할 때 사용할 함수입니다.
아래 접은 글은 DebertaV3Preprocessor가 실제로 텍스트를 어떻게 처리하는지 상세한 예시입니다.
우리가 다음과 같은 간단한 영어 문장을 전처리한다고 가정해 봅시다:
원본 텍스트: "Let's preprocess this text."
CFG 클래스에는 다음과 같이 설정되어 있다고 가정합니다:
- CFG.preset = "deberta_v3_extra_small_en" (사용할 DeBERTa V3 모델)
- CFG.sequence_length = 15 (모델 입력의 최대 길이)
preprocessor("Let's preprocess this text.")가 호출될 때 내부에서 일어나는 과정을 단계별로 살펴보겠습니다.
1단계: 토큰화 (Tokenization)
- 원본: "Let's preprocess this text."
- DeBERTa V3 토크나이저는 이 문장을 다음과 같이 분리할 수 있습니다: ['[CLS]', ' Let', "'s", ' pre', 'process', ' this', ' text', '.', '[SEP]']
- 결과 (토큰 리스트): ['[CLS]', ' Let', "'s", ' pre', 'process', ' this', ' text', '.', '[SEP]']
2단계: 정수 인코딩 (Integer Encoding)
- 설명: 1단계에서 얻은 각 토큰을 모델 어휘사전에 정의된 고유한 숫자 ID로 변환합니다.
- 토큰 리스트: ['[CLS]', ' Let', "'s", ' pre', 'process', ' this', ' text', '.', '[SEP]']
- 각 토큰에 해당하는 숫자 ID (아래 ID는 예시이며, 실제 ID와는 다릅니다):
- '[CLS]' ➡️ 101
- ' Let' ➡️ 1500
- "'s" ➡️ 1023
- ' pre' ➡️ 2835
- 'process' ➡️ 7890
- ' this' ➡️ 1100
- ' text' ➡️ 3000
- '.' ➡️ 119
- '[SEP]' ➡️ 102
- 각 토큰에 해당하는 숫자 ID (아래 ID는 예시이며, 실제 ID와는 다릅니다):
- 결과 (숫자 ID 리스트): [101, 1500, 1023, 2835, 7890, 1100, 3000, 119, 102]
3단계: 패딩 (Padding) / 절단 (Truncation)
- 설명: 모델은 고정된 길이의 입력만 받을 수 있습니다. CFG.sequence_length가 15로 설정되어 있으므로, 모든 입력은 길이가 15가 되어야 합니다.
- 패딩: 토큰화된 ID 리스트의 길이가 15보다 짧으면, 부족한 만큼 리스트의 끝에 특별한 '패딩 토큰 ID'(보통 0)를 채워 넣어 길이를 15로 맞춥니다.
- 절단: 만약 ID 리스트의 길이가 15보다 길면, 15개를 초과하는 부분은 잘라냅니다.
- 과정:
- 현재 ID 리스트: [101, 1500, 1023, 2835, 7890, 1100, 3000, 119, 102] (길이 9)
- sequence_length (15)보다 짧으므로 패딩이 필요합니다. 필요한 패딩 토큰 개수: 15 - 9 = 6개.
- 결과 (token_ids): [101, 1500, 1023, 2835, 7890, 1100, 3000, 119, 102, 0, 0, 0, 0, 0, 0] (길이가 15로 맞춰졌습니다.)
4단계: 패딩 마스크 생성 (Padding Mask Generation)
- 설명: 모델에게 어떤 부분이 실제 의미 있는 토큰이고, 어떤 부분이 길이를 맞추기 위해 추가된 패딩 토큰인지 알려주기 위한 '마스크'를 만듭니다. 모델은 이 마스크를 보고 패딩 부분은 무시하고 실제 의미 있는 토큰에만 집중(어텐션)할 수 있습니다.
- 과정:
- token_ids: [101, 1500, 1023, 2835, 7890, 1100, 3000, 119, 102, 0, 0, 0, 0, 0, 0]
- 실제 토큰 위치는 1로, 패딩 토큰 위치는 0으로 표시합니다.
- 결과 (padding_mask): [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0] (길이 15)
최종 출력
{
'token_ids': [101, 1500, 1023, 2835, 7890, 1100, 3000, 119, 102, 0, 0, 0, 0, 0, 0],
'padding_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]
}3.3 데이터로더
이제 데이터셋을 텐서플로우 파이프 라인에 올립니다.
def build_dataset(texts, labels=None, batch_size=32,
cache=True, shuffle=1024):
# AUTOTUNE: TensorFlow가 병렬 처리를 위한 최적의 스레드 수를 동적으로 결정하도록 설정
AUTO = tf.data.AUTOTUNE
# 입력 데이터(texts)와 레이블(labels)을 묶어 슬라이스(slices) 생성
# 레이블이 있다면, 원-핫 인코딩(to_categorical)하여 3개의 클래스로 변환
slices = (texts,) if labels is None else (texts, keras.utils.to_categorical(labels, num_classes=3))
# 슬라이스로부터 TensorFlow 데이터셋 객체(ds) 생성
ds = tf.data.Dataset.from_tensor_slices(slices)
# cache가 True이면, 데이터셋을 메모리나 로컬 저장소에 캐시하여 다음 에포크 시 더 빠르게 로드
ds = ds.cache() if cache else ds
# preprocess_fn 함수를 데이터셋의 모든 요소에 병렬로 적용 (텍스트 전처리)
ds = ds.map(preprocess_fn, num_parallel_calls=AUTO)
# 데이터셋 동작 방식을 설정하기 위한 옵션 객체 생성
opt = tf.data.Options()
# shuffle 값이 있다면 (0이 아니라면) 데이터셋을 섞음
if shuffle:
# 지정된 버퍼 크기(shuffle)만큼 데이터를 섞고, 재현성을 위해 시드(seed) 설정
ds = ds.shuffle(shuffle, seed=CFG.seed)
# 셔플링 시 결정적 동작(순서 고정)을 비활성화 (일반적으로 셔플링은 비결정적임)
opt.experimental_deterministic = False
# 데이터셋에 위에서 설정한 옵션 적용
ds = ds.with_options(opt)
# 데이터셋을 지정된 배치 크기(batch_size)로 묶음
# drop_remainder=False: 마지막 배치가 배치 크기보다 작더라도 버리지 않고 사용
ds = ds.batch(batch_size, drop_remainder=False)
# 학습 중 현재 배치를 처리하는 동안 다음 배치를 미리 준비하여 GPU 유휴 시간을 줄임
ds = ds.prefetch(AUTO)
# 최종적으로 구성된 데이터셋 반환
return ds# Train
train_texts = train_df.options.tolist() # Extract training texts
train_labels = train_df.class_label.tolist() # Extract training labels
train_ds = build_dataset(train_texts, train_labels,
batch_size=CFG.batch_size,
shuffle=True)
# Valid
valid_texts = valid_df.options.tolist() # Extract validation texts
valid_labels = valid_df.class_label.tolist() # Extract validation labels
valid_ds = build_dataset(valid_texts, valid_labels,
batch_size=CFG.batch_size,
shuffle=False)3.4 스케줄러
딥러닝 모델을 학습시킬 때 학습률(Learning Rate)을 계획에 따라 동적으로 조절해 주는 Keras 콜백(Callback)을 생성하는 함수입니다.
- 웜업(Warm-up): 학습 초반 몇 에포크(lr_ramp_ep) 동안 학습률을 점진적으로 낮은 값(lr_start)에서 높은 값(lr_max)까지 끌어올립니다. 이는 모델이 안정적으로 학습을 시작하도록 돕습니다.
- 유지(Sustain): 웜업 후, 일정 에포크(lr_sus_ep) 동안 최대 학습률(lr_max)을 유지합니다. (코드에서는 lr_sus_ep가 0이므로 이 단계는 거의 없습니다.)
- 감소(Decay): 그 이후 에포크부터는 학습률을 점차 줄여나갑니다. 감소 방식은 mode 매개변수에 따라 달라집니다:
- 'cos' (코사인 감쇠): 코사인 함수 모양으로 부드럽게 학습률을 최솟값(lr_min)까지 줄입니다. (가장 많이 사용되는 방식 중 하나)
- 'exp' (지수 감쇠): 지수적으로 학습률을 줄입니다.
- 'step' (계단식 감쇠): 특정 주기마다 계단처럼 학습률을 줄입니다.
import math
def get_lr_callback(batch_size=8, mode='cos', epochs=10, plot=False):
lr_start, lr_max, lr_min = 1.0e-6, 0.6e-6 * batch_size, 1e-6
lr_ramp_ep, lr_sus_ep, lr_decay = 2, 0, 0.8
def lrfn(epoch): # Learning rate update function
if epoch < lr_ramp_ep: lr = (lr_max - lr_start) / lr_ramp_ep * epoch + lr_start
elif epoch < lr_ramp_ep + lr_sus_ep: lr = lr_max
elif mode == 'exp': lr = (lr_max - lr_min) * lr_decay**(epoch - lr_ramp_ep - lr_sus_ep) + lr_min
elif mode == 'step': lr = lr_max * lr_decay**((epoch - lr_ramp_ep - lr_sus_ep) // 2)
elif mode == 'cos':
decay_total_epochs, decay_epoch_index = epochs - lr_ramp_ep - lr_sus_ep + 3, epoch - lr_ramp_ep - lr_sus_ep
phase = math.pi * decay_epoch_index / decay_total_epochs
lr = (lr_max - lr_min) * 0.5 * (1 + math.cos(phase)) + lr_min
return lr
if plot: # Plot lr curve if plot is True
plt.figure(figsize=(10, 5))
plt.plot(np.arange(epochs), [lrfn(epoch) for epoch in np.arange(epochs)], marker='o')
plt.xlabel('epoch'); plt.ylabel('lr')
plt.title('LR Scheduler')
plt.show()
return keras.callbacks.LearningRateScheduler(lrfn, verbose=False) # Create lr callbacklr_cb = get_lr_callback(CFG.batch_size, plot=True)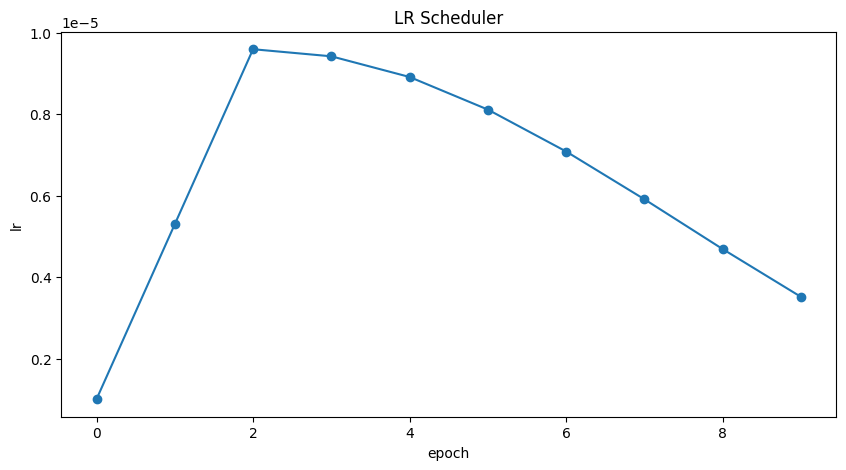
3.5 모델 체크포인팅
훈련 중 가장 좋은 성능을 보이는 모델의 가중치를 저장하는 콜백을 설정합니다.
ckpt_cb = keras.callbacks.ModelCheckpoint(f'best_model.weights.h5',
monitor='val_log_loss',
save_best_only=True,
save_weights_only=True,
mode='min') # Get Model checkpoint callback3.6 대회 지표 적용 (log loss)
이 대회의 지표는 로그 손실(Log Loss) 입니다 .

Keras 라이브러리에 이미 이 지표가 구현되어 있으므로, 가져다 쓰면 됩니다!
log_loss = keras.metrics.CategoricalCrossentropy(name="log_loss")3.7 모델링 및 컴파일
먼저 우리의 input은 임베딩된 벡터라는 것을 기억하고 갑시다!
# 입력 레이어 정의 / 기호적 텐서이므로 앞으로 실제 계산이 이뤄지지 않는다는 것!
inputs = {
"token_ids": keras.Input(shape=(2, None), dtype=tf.int32, name="token_ids"),
"padding_mask": keras.Input(shape=(2, None), dtype=tf.int32, name="padding_mask"),
}
# DebertaV3Classifier backbone을 만듭니다.
backbone = keras_nlp.models.DebertaV3Backbone.from_preset(
CFG.preset,
)
# 첫 번째 응답 (프롬프트 + 응답 A)에 대한 임베딩 계산
response_a = {k: v[:, 0, :] for k, v in inputs.items()} #(v가 아마 batch,p,ra 일듯합니다)
embed_a = backbone(response_a)
# 두 번째 응답 (프롬프트 + 응답 B)에 대한 임베딩 계산 (동일한 백본 모델 사용)
response_b = {k: v[:, 1, :] for k, v in inputs.items()}
embed_b = backbone(response_b)
# 최종 출력 계산
embeds = keras.layers.Concatenate(axis=-1)([embed_a, embed_b]) # 두 응답의 임베딩을 마지막 축 기준으로 합침
embeds = keras.layers.GlobalAveragePooling1D()(embeds) # 합쳐진 임베딩에 대해 전역 평균 풀링 적용 (시퀀스 차원 축소)
outputs = keras.layers.Dense(3, activation="softmax", name="classifier")(embeds) # 3개의 클래스(A 승, B 승, 무승부)에 대한 확률 출력 (Dense + Softmax)
model = keras.Model(inputs, outputs) # 정의된 입력과 출력을 사용하여 Keras 모델 생성
# 옵티마이저, 손실 함수, 평가지표를 설정하여 모델 컴파일
model.compile(
optimizer=keras.optimizers.Adam(5e-6), # Adam 옵티마이저 사용, 학습률 5e-6
loss=keras.losses.CategoricalCrossentropy(label_smoothing=0.02), # 범주형 교차 엔트로피 손실 함수 (레이블 스무딩 0.02 적용)
metrics=[
log_loss, # log_loss 평가지표 (사용자 정의 또는 라이브러리 제공)
keras.metrics.CategoricalAccuracy(name="accuracy"), # 정확도 평가지표
],
)
이게 도대체 무슨 말인지 이해해 보도록 합시다. (압도당해 버린 나..)

개별 처리 및 임베딩 생성:
- 모델은 먼저 (프롬프트 + 응답 A) 조합을 입력으로 받아 처리합니다. 이때 DeBERTa 백본(사전학습된 LLM)를 사용하여 이 조합의 문맥적 의미를 담은 숫자 표현, 즉 새로운 임베딩(embedding)을 생성합니다.
- 마찬가지로 (프롬프트 + 응답 B) 조합도 동일한 모델(동일한 가중치 공유)을 사용하여 별도로 처리하고, 이에 대한 임베딩을 생성합니다.
- 가중치 공유(Weight Sharing): 다이어그램에서는 마치 두 개의 다른 모델이 있는 것처럼 보일 수 있지만, 실제로는 하나의 DeBERTa 모델이 응답 A와 응답 B를 순차적 또는 병렬적으로 처리합니다. 이렇게 동일한 가중치를 사용함으로써 모델은 일관된 기준으로 각 응답을 평가할 수 있습니다.
정보 결합 및 요약:
- 이렇게 얻은 두개의 임베딩을 하나로 연결(concatenate)합니다. 이를 통해 두 응답의 정보를 나란히 비교할 수 있는 통합된 표현이 만들어집니다.
- 연결된 임베딩에 풀링(pooling) 계층을 적용합니다. 풀링은 긴 시퀀스의 임베딩 정보에서 핵심적인 특징을 요약하여 고정된 크기의 벡터로 만듭니다.
최종 판단 (분류):
- 요약된 벡터는 분류기(classifier), 즉 하나 이상의 Dense (또는 Linear) 레이어로 전달됩니다. (코드의 outputs 부분)
- 이 분류기는 최종적으로 softmax 활성화 함수를 통해 세 가지 가능한 결과에 대한 확률을 계산합니다:
- winner_model_a: A 응답이 더 낫다.
- winner_model_b: B 응답이 더 낫다.
- draw: 두 응답이 비슷하거나 무승부이다.
CODE 연결고리 추적:
- inputs: 모델의 시작점입니다.
- response_a, response_b: inputs에서 특정 부분을 잘라낸(slicing) 결과로, 여전히 inputs와의 연결 정보를 가집니다.
- embed_a = backbone(response_a): backbone 레이어는 response_a라는 기호적 텐서를 입력으로 받아, embed_a라는 새로운 기호적 텐서를 출력합니다. embed_a는 자신이 backbone으로부터, 그리고 response_a로부터 왔다는 것을 "알고" 있습니다. embed_b도 마찬가지입니다.
- embeds = keras.layers.Concatenate(axis=-1)([embed_a, embed_b]): Concatenate 레이어는 embed_a와 embed_b를 입력으로 받아, 이 둘이 합쳐진 결과를 나타내는 새로운 기호적 텐서 embeds를 만듭니다.
- embeds = keras.layers.GlobalAveragePooling1D()(embeds): 이전 단계의 embeds(합쳐진 것)를 입력으로 받아, 풀링된 결과를 나타내는 기호적 텐서로 embeds 변수가 업데이트됩니다. (변수 이름을 재사용한 경우입니다.)
- outputs = keras.layers.Dense(...)(embeds): 마지막으로, 풀링된 embeds를 입력으로 받아 최종 outputs 기호적 텐서를 생성합니다. (softmax를 통과하므로 확률이 나옵니다.)
model.summary()Model: "functional_1"
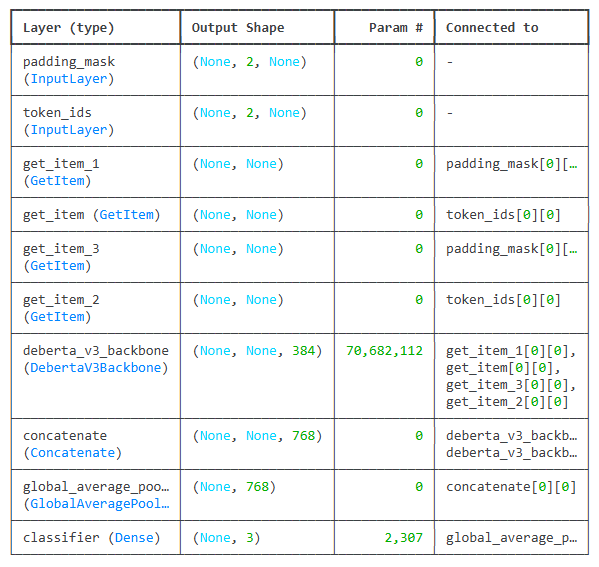
Total params: 70,684,419 (269.64 MB)
Trainable params: 70,684,419 (269.64 MB)
Non-trainable params: 0 (0.00 B)4. 훈련 및 평가
4.1 훈련
# Start training the model
history = model.fit(
train_ds,
epochs=CFG.epochs,
validation_data=valid_ds,
callbacks=[lr_cb, ckpt_cb]
)Epoch 1/3
2874/2874 ━━━━━━━━━━━━━━━━━━━━ 2756s 949ms/step - accuracy: 0.3865 - log_loss: 1.1497 - loss: 1.1507 - val_accuracy: 0.4376 - val_log_loss: 1.0643 - val_loss: 1.0662 - learning_rate: 1.0000e-06
Epoch 2/3
2874/2874 ━━━━━━━━━━━━━━━━━━━━ 2684s 926ms/step - accuracy: 0.4412 - log_loss: 1.0632 - loss: 1.0652 - val_accuracy: 0.4670 - val_log_loss: 1.0425 - val_loss: 1.0452 - learning_rate: 5.3000e-06
Epoch 3/3
2874/2874 ━━━━━━━━━━━━━━━━━━━━ 2654s 923ms/step - accuracy: 0.4653 - log_loss: 1.0394 - loss: 1.0422 - val_accuracy: 0.4685 - val_log_loss: 1.0352 - val_loss: 1.0383 - learning_rate: 9.6000e-064.2 최상의 모델 로드
model.load_weights('/kaggle/working/best_model.weights.h5')4.3 예측
# Build test dataset
test_texts = test_df.options.tolist()
test_ds = build_dataset(test_texts,
batch_size=min(len(test_df), CFG.batch_size),
shuffle=False)
# Make predictions using the trained model on test data
test_preds = model.predict(test_ds, verbose=1)4.4 제출
sub_df = test_df[["id"]].copy()
sub_df[CFG.class_names] = test_preds.tolist()
sub_df.to_csv("submission.csv", index=False)
sub_df.head() ID 우승자_모델_a 우승자_모델_B 승자_무승부
0 136060 0.227417 0.241211 0.531250
1 211333 0.258545 0.329590 0.411865
2 1233961 0.172241 0.457520 0.369873
후기
임베딩하고 텍스트 전처리하고... 이런 건 대학 인공지능 수업 때 감정 분류? 그거 하면서 마지막으로 해본 게 전부였거든요. 근데 이번 Keras NLP 튜토리얼은 가장 기본적인 거라고 하는데도 이해하는 데 좀 애먹은 부분이 많은 것 같아요. 네, 좀 힘들었다고 할 수 있겠습니다. 그치만... 재미는 있었는걸요? ㅎㅎ
사실 이 글(튜토리얼 정리)은 한 3일 정도 작업하다가, 중간에 앱 만들기에 한 3주 집중하고 + 제가 또 군대에 있다 보니... 끝까지 하는 데 좀 오래 걸렸네요.
튜토리얼 저자는 이런 추가 과제들도 더 해보라고 하더라고요:
- 더 큰 모델 사용 (DeBERTa-Base, Gemma 등)
- 최대 토큰 길이 증가
- 5겹 교차 검증 및 앙상블
- 데이터 증강 (응답 순서 섞기 등)
- 더 많은 에포크 훈련
- 학습률 스케줄러 조정
근데... 제가 이걸 할까요? ㅎㅎ GPU 자원도 없어서... 못할 것 같아요. 이 글에 올린 코드도 원래 캐글 노트북으로 돌려봤어야 했는데, 솔직히 너무 귀찮고 학습도 오래 걸릴 것 같아서 (결국) 안 돌려봤습니다. 혹시 코드에 오류 나면... 음... 죄송합니다! 😅
그래도, 하면서 의문이 들거나 진짜 이해 안 되는 부분들은 나름 자세히 설명을 해뒀다고 자부해요. 제가 설명하기 너무 힘든 부분들 같은 건 외부 링크도 걸어놨으니, 가서 보시면 될 겁니다.
다음 캐글 노트북 후기는 언제 올릴지 모르겠지만... 생각보다 빠를 수도 있고요. 앱 만들기가 재미 없어지면 돌아오겠습니다.
작별인사! 👋