🏡 Housing Prices Competition 문제풀이 - 2. 데이터 처리
데이터 분석을 통해 중요한 통찰을 얻은 후, 이를 바탕으로 머신러닝 모델이 학습할 수 있도록 데이터를 깔끔하게 정리해야 합니다. 단지 보기 좋은 그래프를 만들 기 위해, 시각화와 분석을 진행하는 것이 아니라, 전처리에 필수적입니다. 이 글에서는 전처리(Preprocessing)의 핵심 단계들을 다룹니다.
📚 시리즈 전체 목차
🔎 글 개요
모델 학습 전에 데이터를 정제하고 구성하는 작업은 필수입니다. 이 글에서는 결측치 처리, 이상치 제거, 불필요한 변수 제거, 그리고 순서형 변수 인코딩까지 머신러닝에 적합한 형태로 데이터를 다듬는 과정을 자세히 다룹니다. 주택 가격 예측 문제에서 모델 성능을 끌어올리기 위한 핵심 전처리 기술을 실습과 함께 익혀봅니다.
🗂️ 글 내부 목차
1. 중복 기능 제거
1.1 상관관계 기반 피처 제거
먼저 다중공선성 문제를 피하기 위해, 상관계수가 높은 피처 중 하나를 제거합니다.
- GarageYrBlt ↔ YearBuilt
- TotRmsAbvGrd ↔ GrLivArea
- 1stFlrSF ↔ TotalBsmtSF
- GarageArea ↔ GarageCars
X.drop(['GarageYrBlt','TotRmsAbvGrd','1stFlrSF','GarageCars'], axis=1, inplace=True)1.2 누락값이 많은 피처 제거
결측값이 많아 정보성이 떨어지는 피처는 제거하는게 일반적인 방법입니다.
plt.figure(figsize=(25,8))
plt.title('Number of missing rows')
missing_count = pd.DataFrame(X.isnull().sum(), columns=['sum']).sort_values(by='sum', ascending=False).head(20).reset_index()
missing_count.columns = ['features','sum']
sns.barplot(x='features',y='sum', data=missing_count)
위 그래프를 보면 PoolQC, MiscFeature, Alley는 누락된 값이 너무 많다는 것을 알 수 있습니다. 누락값의 비율이 어느정도일때, 해당 피처를 제거하는지에 대한 통찰은 나중에 살펴보도록 합시다. 이런 열은 유용한 정보를 제공할 수 없기에 제거하도록 합시다.
X.drop(['PoolQC','MiscFeature','Alley'], axis=1, inplace=True) #누락값 1,2,3위 제거1.3 목표 변수와 선형 관계가 없는 피처 제거
목표 변수(SalePrice)와 선형 관계가 없거나 특별한 관계를 나타내지 않는 피처는 제거하는 것이 바람직합니다. 이 피처들이 포함될 경우, 모델에 불필요한 노이즈를 추가하고 성능을 저하시킬 수 있기 때문입니다.
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
sns.regplot(x=numeric_train['MoSold'], y='SalePrice', data=numeric_train, ax=axes[0], line_kws={'color':'black'})
sns.regplot(x=numeric_train['YrSold'], y='SalePrice', data=numeric_train, ax=axes[1], line_kws={'color':'black'})
fig.tight_layout(pad=2.0)
X.drop(['MoSold','YrSold'], axis=1, inplace=True)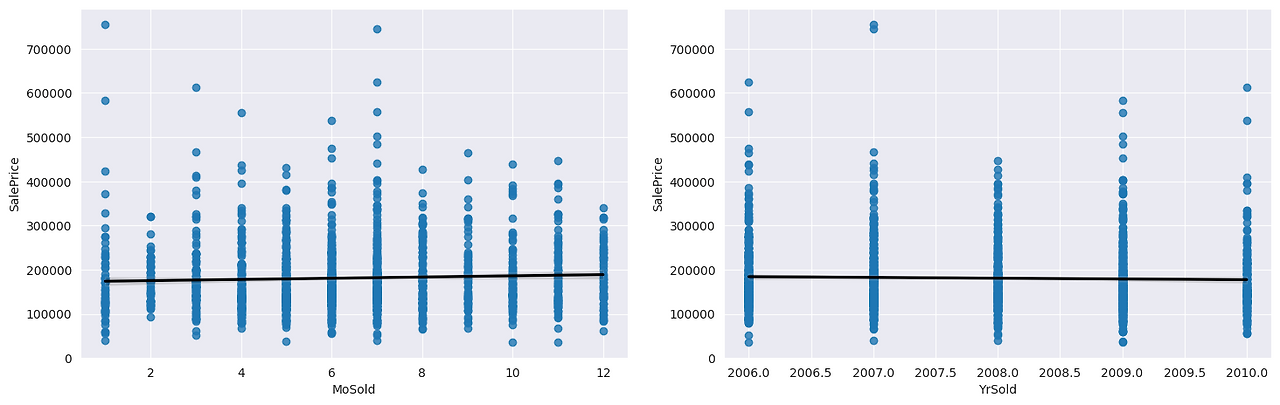
MoSold와 YrSold는 주택 가격인 SalePrice와 선형적인 관계가 거의 없으며, 이를 시각화한 그래프에서도 별다른 패턴이나 관계를 확인할 수 있었습니다. 따라서 이 변수들은 모델링 과정에서 불필요한 영향을 줄 수 있으므로, 제거하는 것이 바람직합니다.
correlation[['SalePrice']].sort_values(['SalePrice'], ascending=False).tail(10)
#상관관계(선형관계)가 낮은 열 보기 (전 블로그 글 참조)
X.drop(['MoSold','YrSold'], axis=1, inplace=True)1.4 단일 값 비율 >96%인 과적합 우려 피처 제거
일부 피처는 데이터의 거의 모든 값이 동일하여, 모델이 해당 변수를 통해 유의미한 패턴을 학습할 수 없습니다. 이러한 변수는 과적합의 위험을 증가시키고, 모델 성능에 도움을 주지 않으므로 제거하는 것이 좋습니다. 이를 위해 각 변수의 값들이 데이터의 96% 이상을 차지하는지 확인하고, 이 조건을 만족하는 변수는 제거합니다.
cat_col = X.select_dtypes(include=['object']).columns
overfit_cat = []
for i in cat_col:
counts = X[i].value_counts()
if counts.iloc[0] / len(X) * 100 > 96:
overfit_cat.append(i)
num_col = X.select_dtypes(exclude=['object']).drop(['MSSubClass'], axis=1).columns
#전 글에서 MSSubClass는 실제로 object로 분류하기로 했었습니다.
overfit_num = []
for i in num_col:
counts = X[i].value_counts()
if counts.iloc[0] / len(X) * 100 > 96:
overfit_num.append(i)
X.drop(overfit_cat + overfit_num, axis=1, inplace=True)print("Categorical Features with >96% of the same value: ",overfit_cat)
print("Numerical Features with >96% of the same value: ",overfit_num)Categorical Features with >96% of the same value: ['Street', 'Utilities', 'Condition2', 'RoofMatl', 'Heating']
Numerical Features with >96% of the same value: ['LowQualFinSF', '3SsnPorch', 'PoolArea', 'MiscVal']
2. 이상치 처리
이번 단계는 이상치 처리를 통해 모델이 극단적인 값에 의해 영향을 받지 않도록 하는 과정입니다. 이를 통해 모델의 성능이 안정적이고 정확하게 나올 수 있도록 합니다. 이상치를 적절하게 처리하지 않으면 모델이 잘못된 예측을 할 위험이 있기 때문에, 이를 제거하는 것이 중요합니다.
2.1 이상치 탐지 (박스플롯)
이전글 boxplot에서 극단적인 이상치가 있는 다음 특징을 파악했습니다.
- LotFrontage
- LotArea
- BsmtFinSF1
- TotalBsmtSF
- GrLivArea
out_col = ['LotFrontage','LotArea','BsmtFinSF1','TotalBsmtSF','GrLivArea']
fig = plt.figure(figsize=(20,5))
for index, col in enumerate(out_col):
plt.subplot(1,5,index+1)
sns.boxplot(y=col, data=X)
fig.tight_layout(pad=1.5)
2.2 임계값 기반 이상치 제거
이상치를 시각적으로 확인한 후, 임계값(Threshold)을 설정하여 이상치를 제거하는 방법을 사용합니다. 여기서는 특정 변수에 대해 극단적인 값을 기준으로 이상치를 제거합니다.
train = train.drop(train[train['LotFrontage'] > 200].index) # 그래프를 확인하면 200위에 데이터는 얼마 없다는 걸 알 수 있다.
train = train.drop(train[train['LotArea'] > 100000].index)
train = train.drop(train[train['BsmtFinSF1'] > 4000].index)
train = train.drop(train[train['TotalBsmtSF'] > 5000].index)
train = train.drop(train[train['GrLivArea'] > 4000].index)3. 결측치 채우기
결측치를 채우는 궁극적인 이유는 모델 학습의 효율성을 높이고, 예측 정확도를 향상시키며, 분석의 신뢰성을 확보하기 위함입니다. 결측치를 무시하고 데이터를 처리할 수는 없지만(머신러닝 모델은 누락된 값을 처리할 수 없습니다.), 결측치를 적절하게 처리하는 방식(예: NA, 평균, 중앙값 등)을 선택함으로써, 데이터의 본래 의미를 유지하면서도 모델이 최적의 성능을 낼 수 있도록 도울 수 있습니다.
3.1 결측치 현황 확인
pd.DataFrame(X.isnull().sum(), columns=['sum']).sort_values(by='sum', ascending=False).head(15) sum
Fence 2348
MasVnrType 1766
FireplaceQu 1420
LotFrontage 486
GarageCond 159
GarageQual 159
GarageFinish 159
GarageType 157
BsmtExposure 82
BsmtCond 82
BsmtQual 81
BsmtFinType2 80
BsmtFinType1 79
MasVnrArea 23
MSZoning 4Fence 피처에는 2348개의 결측치가 있다는 것을 알 수 있습니다.
3.2 순서형 피처 NA 대체
의미 있는 순서가 있는 경우, 결측값은 “NA”로 대체하여 분석에 반영합니다.
cat = ['GarageType','GarageFinish','BsmtFinType2','BsmtExposure','BsmtFinType1',
'GarageCond','GarageQual','BsmtCond','BsmtQual','FireplaceQu','Fence',
"KitchenQual","HeatingQC",'ExterQual','ExterCond']
X[cat] = X[cat].fillna("NA")순서형 피처는 값들 사이에 명확한 순서나 등급이 있기 때문에 결측치를 처리할 때 단순히 평균이나 중앙값으로 대체하는 것이 적절하지 않을 수 있습니다. 예를 들어, ExterQual (외부 품질) 변수는 "Ex" (최고), "Gd" (좋음), "TA" (평균), "Fa" (나쁨), "Po" (최악) 등등의 값들을 가질 수 있습니다. 만약 결측치가 있다면, 단순히 평균 값으로 대체하는 것보다는 정보 없음을 의미하는 NA로 처리하는 것이 분석을 더 의미 있게 만들 수 있습니다.
3.3 범주형 피처 최빈값 대체 (Neighborhood별)
Categorical features의 결측값은 지역별 가장 빈번한 카테고리로 대체합니다.
cols = ["MasVnrType", "MSZoning", "Exterior1st", "Exterior2nd", "SaleType", "Electrical", "Functional"]
X[cols] = X.groupby("Neighborhood")[cols].transform(
lambda x: x.fillna(x.mode().iloc[0] if not x.mode().empty else "Unknown")
)범주형 변수에서 결측치를 채울 때는, 그 변수의 가장 빈번한 값(최빈값)을 사용하는 방법이 일반적입니다. 그러나 단순히 전역적으로 최빈값을 적용하기보다는, 각 동네(Neighborhood) 내에서 결측치가 있는 변수들의 가장 자주 나타나는 값을 찾아 결측치를 채우는 방식을 적용했습니다. 이렇게 하면, 특정 동네의 특성에 맞게 결측치가 대체되므로 더 의미 있는 데이터가 만들어집니다.
예를 들어, 어떤 동네에서는 MasVnrType(벽돌 마감재 종류)의 결측치가 있을 때, 그 동네에서 가장 많이 사용되는 마감재 종류를 대체값으로 사용할 수 있습니다. 이렇게 하면, 각 동네의 특성을 고려한 더 정확한 데이터를 제공할 수 있습니다.
3.4 수치형 피처 평균 대체
수치형(numerical) 피처의 결측치는 보통 평균값으로 대체하는 방식이 가장 일반적입니다. 평균값으로 결측치를 대체하면, 데이터의 중앙 경향을 유지하면서 결측치를 처리할 수 있어 분석에서 유용하게 활용됩니다.
cont = ["BsmtHalfBath", "BsmtFullBath", "BsmtFinSF1", "BsmtFinSF2",
"BsmtUnfSF", "TotalBsmtSF", "MasVnrArea"]
X[cont] = X[cont].fillna(X[cont].mean())3.5 지역별 평균값 활용 결측값 대체
어떤 수치형 피처들은 지역(Neighborhood) 에 따라 값의 차이가 클 수 있습니다. 이런 경우, 전체 평균을 사용해 결측치를 대체하면 큰 오차가 발생할 수 있습니다. 이러한 오차는 예측 성능에 영향을 미쳐 모델의 예측 정확도를 낮출 수 있습니다.
기억할 것은, 도메인 지식을 활용하여, 데이터를 이해하고 각 변수의 특성에 맞게 결측치를 처리하는 것이 예측 모델의 성능을 크게 향상시킬 수 있다는 것입니다.
X['LotFrontage'] = X.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.mean()))
X['GarageArea'] = X.groupby('Neighborhood')['GarageArea'].transform(lambda x: x.fillna(x.mean()))
X['MSZoning'] = X.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
#마지막은 MSZoning 변수의 결측치를 각 MSSubClass별로 최빈값을 사용해서 대체하는 코드먼저 LotFrontage와 GarageArea의 전체 평균값을 살펴 보겠습니다.
print("Mean of LotFrontage: ", X['LotFrontage'].mean())
print("Mean of GarageArea: ", X['GarageArea'].mean())Mean of LotFrontage: 69.30579531442663
Mean of GarageArea: 472.8745716244003그런 다음 Neighborhood 에 따른 평균값을 시각화 하겠습니다.
neigh_lot = X.groupby('Neighborhood')['LotFrontage'].mean().reset_index(name='LotFrontage_mean')
neigh_garage = X.groupby('Neighborhood')['GarageArea'].mean().reset_index(name='GarageArea_mean')
fig, axes = plt.subplots(1,2,figsize=(22,8))
axes[0].tick_params(axis='x', rotation=90)
sns.barplot(x='Neighborhood', y='LotFrontage_mean', data=neigh_lot, ax=axes[0])
axes[1].tick_params(axis='x', rotation=90)
sns.barplot(x='Neighborhood', y='GarageArea_mean', data=neigh_garage, ax=axes[1])
4. 데이터 유형 변경 및 순서형 피처 매핑
4.1 MSSubClass 문자열 변환
MSSubClass는 사실상 범주형 피처이므로 문자열로 변환합니다.
X['MSSubClass'] = X['MSSubClass'].apply(str)4.2 순서형 피처 값 매핑 (ExterQual 등)
순서형 피처는 값들 간에 명확한 순서가 존재하는 특성을 가집니다. 피처 값들이 정량적인 의미를 가지게 되어, 모델이 이들을 숫자적으로 이해하고 예측에 활용할 수 있게 만듭니다.
ordinal_map = {'Ex': 5,'Gd': 4, 'TA': 3, 'Fa': 2, 'Po': 1, 'NA':0}
fintype_map = {'GLQ': 6,'ALQ': 5,'BLQ': 4,'Rec': 3,'LwQ': 2,'Unf': 1, 'NA': 0}
expose_map = {'Gd': 4, 'Av': 3, 'Mn': 2, 'No': 1, 'NA': 0}
fence_map = {'GdPrv': 4,'MnPrv': 3,'GdWo': 2, 'MnWw': 1,'NA': 0}
ord_col = ['ExterQual','ExterCond','BsmtQual', 'BsmtCond','HeatingQC','KitchenQual','GarageQual','GarageCond', 'FireplaceQu']
for col in ord_col:
X[col] = X[col].map(ordinal_map)
fin_col = ['BsmtFinType1','BsmtFinType2']
for col in fin_col:
X[col] = X[col].map(fintype_map)
X['BsmtExposure'] = X['BsmtExposure'].map(expose_map)
X['Fence'] = X['Fence'].map(fence_map)이로써 전처리 단계가 완료되었습니다. 다음은 Feature Engineering 단계입니다.
📚 시리즈 전체 목차
- 1. 데이터 이해
- 2. 데이터 전처리
- 3. Feature Engineering
- 4. 모델링 및 앙상블
'캐글 스터디' 카테고리의 다른 글
| [Kaggle] Digit Recognizer Competition : 손글씨 숫자 분류 모델 만들기 - 1. 데이터 준비 (0) | 2025.04.16 |
|---|---|
| [Kaggle] Housing Prices Competition 를 함께 공부하자! - 4. 모델링 및 앙상블 (0) | 2025.04.13 |
| [Kaggle] Housing Prices Competition 를 함께 공부하자! - 3. Feature Engineering (0) | 2025.04.12 |
| [Kaggle] Housing Prices Competition 를 함께 공부하자! - 1. 데이터 이해 (0) | 2025.04.05 |
| [Kaggle] 타이타닉 튜토리얼로 캐글 스터디 시작하기 (1) | 2025.04.01 |