🏡 Housing Prices Competition 문제풀이 - 3. Feature Engineering
피처 엔지니어링은 타겟 변수인 SalePrice를 보다 정확하게 예측할 수 있도록, 기존 데이터를 바탕으로 새로운 피처(변수)를 생성하는 과정입니다. 이 글에서는 주택 관련 도메인 지식을 바탕으로, 예측에 도움이 될 수 있는 새로운 피처들을 만들어보겠습니다.
📚 시리즈 전체 목차
- 1. 데이터 이해
- 2. 데이터 전처리
- 3. Feature Engineering
- 4. 모델링 및 앙상블
🔎 글 개요
이 글에서는 주택 가격 예측 성능을 높이기 위해, 도메인 지식을 바탕으로 의미 있는 새로운 피처를 생성하고 이를 데이터에 반영하는 과정을 소개합니다.
🗂️ 글 내부 목차
1. 추가 피처 생성
도메인 지식을 활용해 주택 가격 예측에 도움이 될 수 있는 새로운 피처들을 생성합니다. 예를 들어, LotFrontage와 LotArea를 더해 총 토지 면적(TotalLot)을 계산하거나, TotalBsmtSF와 2ndFlrSF를 합산해 총 주거 면적(TotalSF)을 계산할 수 있습니다. 이 외에도 반욕조(HalfBath)와 전욕조(FullBath)를 합쳐 총 욕실 수(TotalBath)를 만들고, 다양한 유형의 현관 면적을 더해 총 현관 면적(TotalPorch)을 구하는 식입니다.
X['TotalLot'] = X['LotFrontage'] + X['LotArea']
X['TotalBsmtFin'] = X['BsmtFinSF1'] + X['BsmtFinSF2']
X['TotalSF'] = X['TotalBsmtSF'] + X['2ndFlrSF']
X['TotalBath'] = X['FullBath'] + X['HalfBath']
X['TotalPorch'] = X['OpenPorchSF'] + X['EnclosedPorch'] + X['ScreenPorch']
- TotalLot(총 토지 면적) = LotFrontage + LotArea
- TotalBsmtFin(총 지하실 면적) = BsmtFinSF1 + BsmtFinSF2
- TotalSF(총 주거 면적) = TotalBsmtSF + 2ndFlrSF
- TotalBath(총 욕조 개수) = FullBath + HalfBath
- TotalPorch(총 현관 면적) = OpenPorchSF + EnclosedPorch + ScreenPorch
2. 이진 피처 생성
특정 면적 관련 피처들은 값이 0이면 존재하지 않음, 0보다 크면 존재함을 의미할 수 있습니다. 이러한 특성을 활용해, 각 피처의 존재 유무를 나타내는 이진 피처(binary feature) 를 생성함으로써 모델이 해당 요소의 유무 자체를 학습할 수 있도록 도와줍니다.
다음 열들에 대해 값이 0보다 크면 1, 그렇지 않으면 0으로 변환하는 _bin 접미사의 이진 피처를 추가합니다:
cols = ['MasVnrArea', 'TotalBsmtFin', 'TotalBsmtSF', '2ndFlrSF', 'WoodDeckSF', 'TotalPorch']
for col in cols:
X[col + '_bin'] = X[col].apply(lambda x: 1 if x > 0 else 0)
| MasVnrArea_bin | 외벽 벽돌 마감(석조 마감)의 존재 여부 (MasVnrArea > 0) |
| TotalBsmtFin_bin | 마감된 지하실이 존재하는지 여부 (TotalBsmtFin > 0) |
| TotalBsmtSF_bin | 지하실 자체의 존재 여부 (TotalBsmtSF > 0) |
| 2ndFlrSF_bin | 2층이 존재하는지 여부 (2ndFlrSF > 0) |
| WoodDeckSF_bin | 목재 데크가 존재하는지 여부 (WoodDeckSF > 0) |
| TotalPorch_bin | 현관(포치)이 존재하는지 여부 (TotalPorch > 0) |
이진 피처 생성은 특히 부동산처럼 피처의 유무가 가치를 크게 좌우하는 데이터셋에서 매우 효과적입니다. ( PoolArea 를 데이터 전처리 단계에서 삭제했었는데, 추가하면 모델에 더 나은 성능을 가져올 지도 모르겠습니다.)
3. 범주형 피처 인코딩
머신러닝 모델은 범주형 데이터를 직접적으로 처리할 수 없습니다. 따라서 문자형(범주형) 변수는 모델이 이해할 수 있도록 수치형으로 변환해야 합니다. 이때, 가장 널리 사용되는 방법 중 하나가 바로 원-핫 인코딩(One-Hot Encoding)입니다.
#pandas.get_dummies() 함수를 사용하면,
#각 범주형 변수의 고유한 값들에 대해 0 또는 1로 표시된 새로운 열들을 생성할 수 있습니다.
X = pd.get_dummies(X)One-Hot Encoding은 각 범주에 고유한 수치(순서)를 부여하지 않고 서로 독립된 열로 분리함으로써 잘못된 순서 정보를 피할 수 있습니다. 순서가 중요한 피처의 경우 이전 글에서 순서를 부여했었습니다.
아래는, 원핫 인코딩의 예시입니다.
df = pd.DataFrame({
'Neighborhood': ['CollgCr', 'Veenker', 'Crawfor', 'CollgCr']
})
df_encoded = pd.get_dummies(df, columns=['Neighborhood']) Neighborhood_CollgCr Neighborhood_Crawfor Neighborhood_Veenker
0 1 0 0
1 0 0 1
2 0 1 0
3 1 0 04. 타깃 분포 확인 및 변환
머신러닝 모델은 보통 잔차(residual) 가 정규분포를 따를 때 더 안정적이고 예측 성능이 좋아집니다. 그러므로 타겟 열인 SalePrice의 분포를 확인해서 skewed 되어있는지 확인하겠습니다.
plt.figure(figsize=(10,6))
plt.title("Before transformation of SalePrice")
sns.distplot(train['SalePrice'], norm_hist=False)
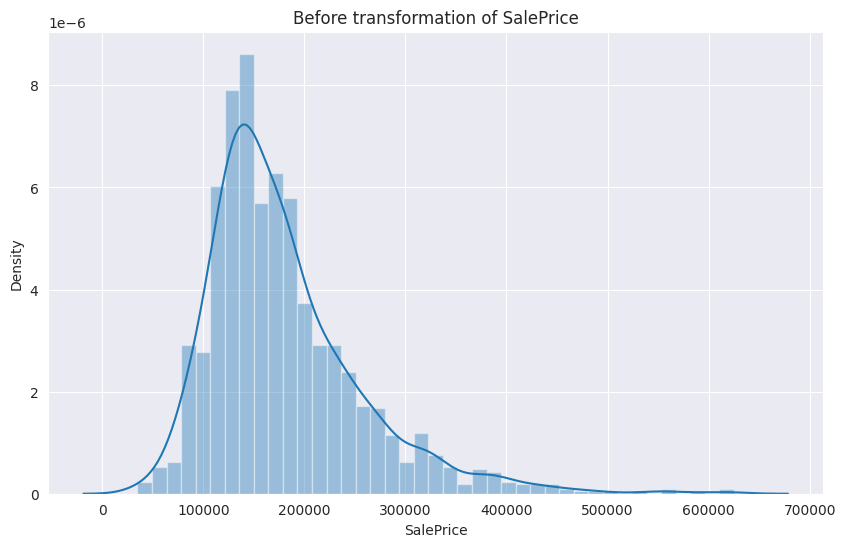
우측으로 긴 꼬리를 확인할 수 있습니다.
이럴 때는 로그 변환(log transformation) 을 적용해 왜도(skewness)를 줄이고, 분산(variance)을 안정화할 수 있습니다.
plt.figure(figsize=(10,6))
plt.title("After transformation of SalePrice")
sns.distplot(np.log(train['SalePrice']), norm_hist=False)

변환된 값을 타깃 변수(y) 에 저장하여 학습에 사용할 준비를 합니다.
y["SalePrice"] = np.log(y['SalePrice'])
📚 시리즈 전체 목차
- 1. 데이터 이해
- 2. 데이터 전처리
- 3. Feature Engineering
- 4. 모델링 및 앙상블
'캐글 스터디' 카테고리의 다른 글
| [Kaggle] Digit Recognizer Competition : 손글씨 숫자 분류 모델 만들기 - 1. 데이터 준비 (0) | 2025.04.16 |
|---|---|
| [Kaggle] Housing Prices Competition 를 함께 공부하자! - 4. 모델링 및 앙상블 (0) | 2025.04.13 |
| [Kaggle] Housing Prices Competition 를 함께 공부하자! - 2. 데이터 전처리 (0) | 2025.04.09 |
| [Kaggle] Housing Prices Competition 를 함께 공부하자! - 1. 데이터 이해 (0) | 2025.04.05 |
| [Kaggle] 타이타닉 튜토리얼로 캐글 스터디 시작하기 (1) | 2025.04.01 |